Benefits of decoupling storage and compute
All data generated by applications or digital systems carries value and can be exploited; however, identifying the relevant data and its efficient consumption requires deep business acumen and analytical orientation. The exponential amount of data being generated across digital channels has forced scholars to find new ways of seeing and analyzing the world. Since capturing, searching, sharing, storing, and analyzing this data requires a massive amount of storage and computational power, organizations are on the look-out for cost-effective options to manage, enrich, and exploit it with reduced investments and greater flexibility.
We have witnessed the adoption of big data management systems like Hadoop etc. Many organizations have been successful in data-driven decision-making using these. However, it comes at a hefty price, and a large pie of these expenses is towards managing large-sized storage and computing systems. Since architecturally, these big data systems require storage and compute together, organizations need to keep adding storage and compute as the data grows. Therefore, to reduce infrastructure provisioning and maintenance costs, organizations have started moving all their analytical workloads to the Cloud. The reason is simple- it brings you scalability, elasticity, and flexibility to disown the infrastructure when it is not required.
The migration of big-data systems to the Cloud has provided flexibility to scale up and down the clusters and accommodate variations in analytic workload. It has also lowered infrastructure costs and enhanced business value; however, cost expenses are still high because traditional big data requires large storage and compute together. Consider an example of an organization moving a Hadoop system to Azure cloud by procuring Azure HD Insights with clusters of nodes as Azure VMs. Although it offers the flexibility to manage infrastructure on demand, it does not save costs because storage and compute are together.
To overcome these challenges, cloud service providers architected separate compute and storage to make them more economical. This results in greater operational flexibility to meet business and stakeholder objectives – a win for any IT organization.
Decoupled Compute and Storage Architecture Use Cases
Cloud adoption and separation of compute and storage brings greater flexibility and cost savings to organizations planning to monetize their data using big data and advanced analytics. Let’s evaluate a few use cases that can benefit from this architecture.
- Let’s consider a large retailer who wants to enhance the overall customer experience by driving insights from its purchase transactions, customer demographics, social data, service history, etc. They will need to transform and process a large amount of data in real-time. Retailer must also consider spikes in volume during a festive or peak season. Such spikes will result in a variable requirement of computing power, whereas the storage considerations are largely not impacted.
- Similarly, let’s assume a transporter of commercial vehicles (equipped with sensors and IoT devices) is planning to analyze its driver’s behavior and vehicle usage to optimize operational costs. It requires them to transform, enrich, and analyze data sets generated by sensors and IoT devices, along with other data sets such as geo-spatial, schedules, driver’s health data and more.
Drive Cost Savings with Decoupled Compute and Storage
The above use cases can be applied to any organization that has large analytics needs. To get a grasp on how immense cost savings can be made by leveraging the separation of compute and storage capabilities, let’s elaborate on the transporter use case.
The transporter’s commercial vehicles will be generating massive data sets from its sensors and IoT devices. In my experience of working with one such large manufacturer, I have noticed that each truck is equipped with motion sensors and an IoT device that generate around 10-15 GB of data each day. Having hundreds of trucks on the road leads to the generation of terabytes of data each month. Adding geo, rosters and other data would warrant even more storage. To drive operational efficiency from all this data, they would require a significant amount of storage and compute. Let’s assume that considering a year of data requirements, the transporter would need at least a few petabytes of storage with a 30-node cluster to generate analytical insights.
Let’s assume the transporter goes for a traditional big data solution. It would require him/her to maintain 30 node clusters year-round. As data increases, they would need to add more and more clusters to suffice additional storage, compute and performance requirements. Instead, if the transporter goes with a decoupled storage and compute-based architecture (see reference Azure Synapse Architecture below), it will result in a lot of cost-saving.
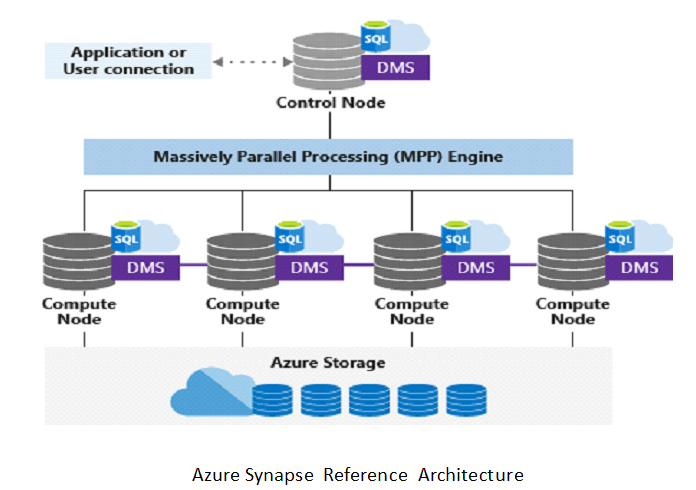
Let’s understand how this architecture enables cost savings. The control node can assess the request received from business or analytics applications and pass it on to the compute nodes for processing. Compute nodes use their DMS (Data Management Services) to locate and process the data from storage. If we closely evaluate this architecture, you would see that compute is only getting used when a request is made by the business or analytical applications, whereas storage is detached and can keep acquiring the data round-the-clock without involving the compute part. Coming back to our use case, since this architecture offers to use compute at will, the transporter can keep acquiring the sensors and IoT data in storage but may decide to use compute only during business hours. This offers a saving of >50% of the cost of compute usage. Similarly, for retailers, without deep-diving into the intricacies of analytics usage and consumption, scaling up and down the compute during the peak and off-season itself will result in a lot of cost savings.
For short-term analytics initiatives, Cloud offerings like Azure Synapse Analytics or AWS EMR with EC2 and S3 allow you to decouple compute and storage- offering a ‘sleep’ functionality. It lets you shut down all compute nodes until you need them again. Come out of sleep when your work starts by resuming with your compute clusters and reviving your database. Lastly, many organizations, depending on the use case require consistent and variable compute.
Organizations need to support the right use cases today, knowing with certainty that they may change in the future. To achieve this, they seek options to buy compute power only when needed and reduce storage costs based on use case requirements.
Zensar has expertise with a majority of prominent and emerging SQL and NoSQL databases, data engineering technologies and data lakes/warehouses options. We have enabled many of our customers to maximize savings on cloud economics and will be glad to partner with you if there is a need to take advantage of Cloud economics without getting hampered by fluctuating requirements and dynamic workloads