Demystifying AI/ML modeling approach for predictive maintenance in manufacturing industries
Read time: 4 mins
Since the first industrial revolution, the manufacturing sector has experienced significant technological advancements every few decades. The second industrial revolution brought about mass production via assembly lines, while the third gave us IT, control systems, and robotic automation. We are in the fourth revolution with new systems such as connected plants, smart factories, the internet of things (IoT), and digital transformation.
Predictive maintenance
As the term suggests, predictive maintenance is the way/process of monitoring the condition of operating equipment to reduce the possibility of unexpected failure. The early onset of predictive maintenance can be traced back to the 1990s with terms such as condition-based monitoring. In the practical world, predictive maintenance can also be as simple as an experienced mechanic listening to the sound of the running machine and predicting the possible problem in the gearbox.
With the advent of the industrial revolution 4.0 and IoT, the equipment suite is now enabled with an array of sensors, and hence using AI/ML data-driven models has gained more traction.
Traditional maintenance
The traditional industrial equipment maintenance method is called preventive maintenance. It’s a proactive approach where the equipment is inspected at fixed intervals regardless of its performance or operational issues. The time interval can also be based on usage hours. For example, typically, car maintenance happens after every 10,000 kilometers.
Although this approach is adapted across industries, it has major drawbacks:
- Due to its proactive nature, there’s little room for improvement in the overall management of the maintenance program.
- It is hard to estimate which section of the machine requires maintenance; hence, the downtime required for each maintenance stop can’t be reduced.
Modeling predictive maintenance problems
The historical operating data can be a good starting point for modeling predictive maintenance problems. Due to robust control systems and IoT sensor packages, any machine can have from ten to a few hundred sensors recording data every few seconds. This is great because just one year of historical data can give the algorithm a few million data points to train.
But does this mean it’s something exceptional? Unfortunately, no. The volume of data can quickly turn into redundant data due to the following reasons:
- Industrial machines are built to last. So, there can be little to no observable failures in historical data.
- Robust control and backup systems are designed to keep the machine operating under a tightly controlled regime.
- There is no industry-wide standardization in how the maintenance data is logged and hence little to no annotation of historical failure events.
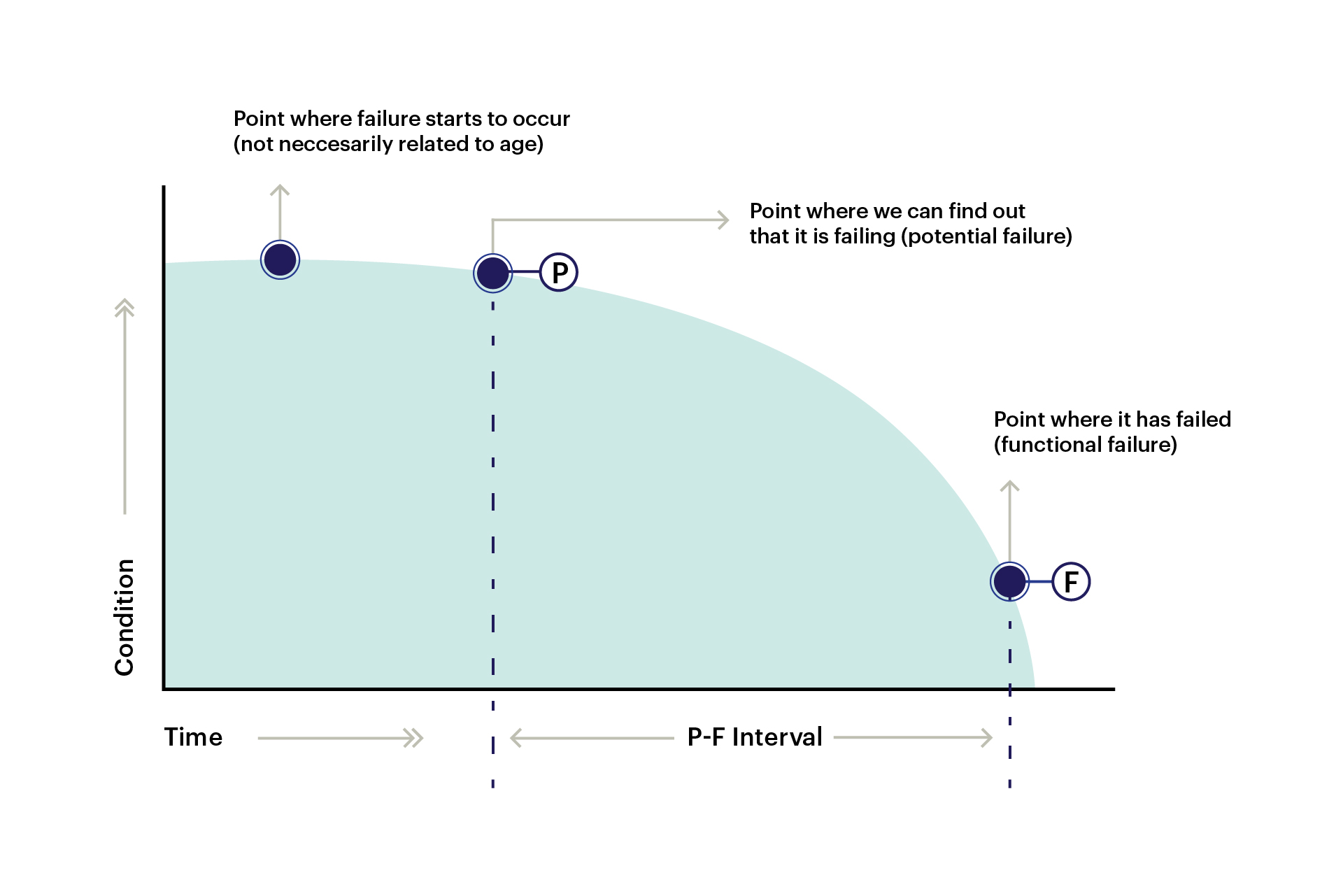 Fig 1: P-F curve for equipment degradation stages
Fig 1: P-F curve for equipment degradation stages
This indicates that class imbalance (unequal distribution and variation of data in machine learning tasks) is a considerable problem when modeling such data. To decide on a preferable modeling approach, let’s first list down the questions that any model should answer:
- Anomaly detection: Which part of the machine is showing signs of degradation?
- Remaining useful life (RUL): How long can the machine run before it fails and stops?
- Diagnostics: Combination of anomaly signals to predict failure mode. Failure modes are annotations of the type of failure.
Having distributed problems in the above categories, we can now take independent approaches to solve and perfect individual models.
Anomaly detection
Anomaly detection can be modeled for every signal or subset of signals. The selection can be based on the possibility of failure if that signal starts to deviate despite the machine’s regular operation. E.g., the bearing temperature in the gearbox varies in sync with its RPM. If the bearing temp increases despite constant RPM, a clear decorrelation suggests a possible anomaly.
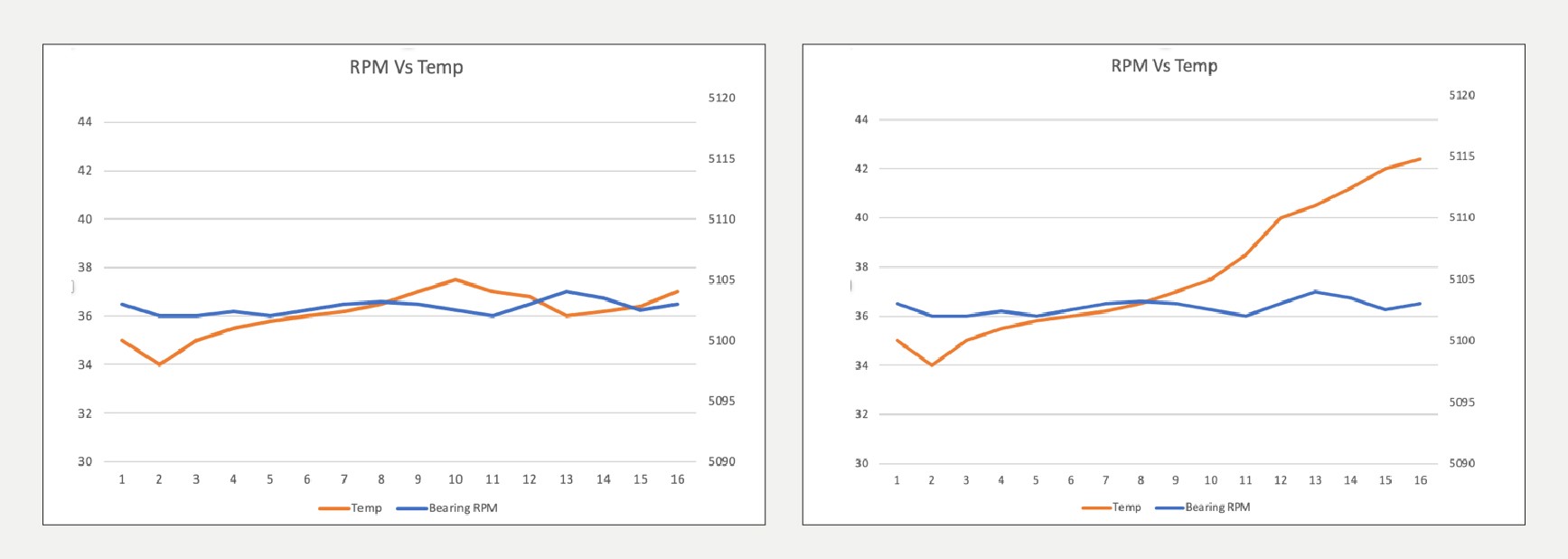
Fig 2: Bearing temp variation — normal (left) vs. anomaly (right)
Before it turns into an anomaly, the deviation percentage can be learned from its historical behavior. An excellent statistical baseline can be five times the standard deviation observed over a historical average operation period.
The anomaly detection problem can be modeled as a multivariate clustering problem. Signals should be grouped based on mechanical properties, typical usage behavior, and environmental operating conditions. The domain specialist can provide valuable insight into such queries.
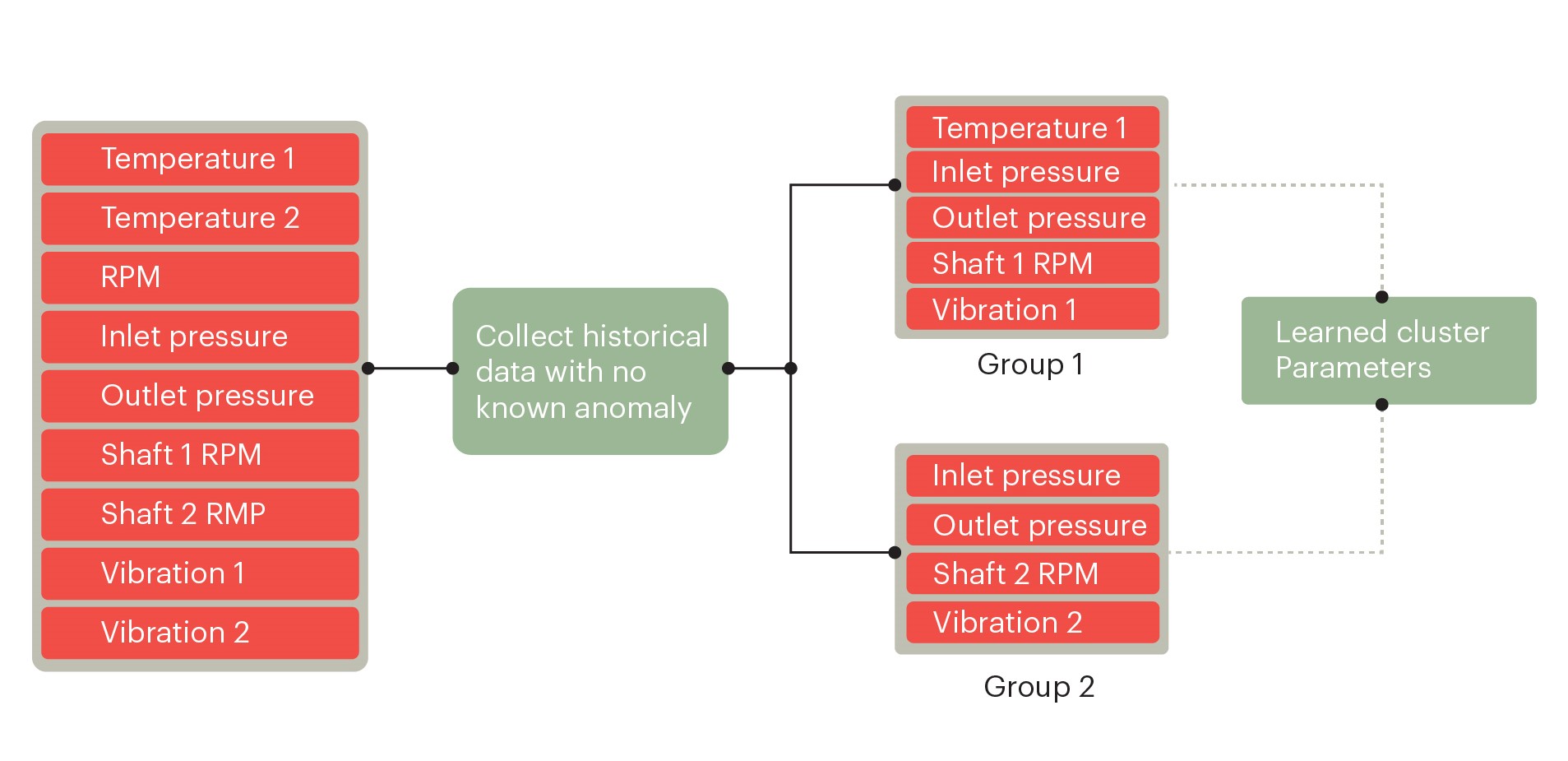 Fig 3: A clustering approach
Fig 3: A clustering approach
Remaining useful life (RUL)
Anomaly detection alone is insufficient evidence to conclude that the machine might be at risk of failure. This is because such deviations are a common occurrence in day-to-day operations. To consider the detected anomaly genuinely concerning, it must sustain for a sufficiently long time, followed by continuous degradation.
From our bearing temperature example, bearing temperature starts to increase and crosses the anomaly threshold. It then continues to rise despite other parameters showing no sign of deviation.
The estimation of RUL can be treated as a time series problem. Parameter variation from the point when the anomaly is flagged can be used to forecast future values. The target limit value can be the maximum allowable limit (also called alarm limit) set in the respective control system.
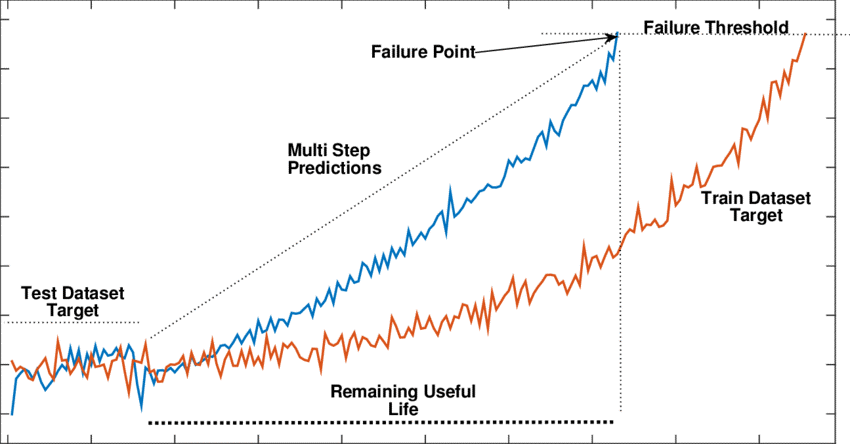
Fig 4: Degradation of signals and RUL
Diagnostics
With the information of anomaly and RUL over signals, we can combine them to predict the possible failure type as a classification approach. This can also be modeled as a multiclass classification problem. However, the scenario can be challenging to implement as it needs historical data with the correct annotation of failure type — information that can be hard to get and may require domain expert advice to label the events.
The failure mode can be labeled as breakdown events such as overheating, part breakdown, etc. The most well-known classification approaches can work if they can handle large-class imbalances.
Conclusion
There is great potential for applying AI/ML models in manufacturing, and predictive maintenance is crucial. Additionally, a lot of information is available on historical operation data. But due to the lack of annotation and standardization, modeling it via the traditional AI/ML approach can be difficult. There is a clear need to use innovative ways to model these problems by breaking them into smaller sets of sub-problems. An experienced partner in this field can make navigating these challenges much easier and faster. However, in the future, with the availability of more labeled data, we may see the possibility of using more complex models.