Managing Generative AI’s Unfolding Knowledge and Innovation Capabilities
OpenAI’s ChatGPT hit a remarkable milestone by amassing a million users in just under a week. Then, surpassing all expectations, it skyrocketed to an astounding 100 million users within a mere two months. There is extraordinary interest and excitement surrounding this cutting-edge technology. Enterprises have recognized the immense potential of these large language models (LLMs), envisioning their applications across a diverse array of scenarios.
The big question across all enterprises is: “How can I develop a system akin to ChatGPT, utilizing my own data as the foundation for generating responses?”
Indeed, the truth is that not every organization has access to the vast amount of data required to develop their own large language models. Instead of generating the models from scratch, the best option is to enhance an existing large language model with custom knowledge/domain knowledge.
Fine-tuning and in-context learning using retrieval-augmented generation (RAG) are two crucial approaches for utilizing generative AI models, especially when dealing with custom datasets and domain-specific use cases.
Fine-tuning
Fine-tuning involves taking a pre-existing generative AI model, such as GPT-3, and training it further using a custom dataset specific to an organization’s domain or needs. This process allows the model to adapt and become more accurate in generating responses relevant to the desired context. Fine-tuning can significantly enhance the model’s performance and cater to the organization’s unique requirements. However, it comes with some challenges, including the need for an adequate amount of high-quality labeled data and substantial computational resources. Additionally, hosting a custom fine-tuned model can incur additional costs, making it important for organizations to weigh the benefits against the investment.
In-context learning using retrieval-augmented generation
In-context learning is a technique where, during the querying process, relevant information from the custom dataset is supplied alongside the user query. By providing this contextual information, the generative AI model can better understand and respond to the specific task or domain at hand. This method is more cost-effective compared to fine-tuning, as it doesn’t require training a separate model from scratch. However, it is constrained by the model’s token limit, which means the amount of contextual information that can be supplied is limited.
The choice between the two approaches depends on factors such as the availability of data, budget considerations, and the level of customization required for the desired application.
Off-late in-context learning using retrieval-augmented generation has seen a lot of traction because of the benefits it brings in. It is a method that combines generative AI with a retrieval mechanism. In this approach, the model has access to a database of relevant information, and during the generation process, it can retrieve and integrate content from this database to improve the accuracy and relevance of its responses.
In RAG, external data can originate from various sources, including document repositories, databases, or APIs. The first step is to convert the documents and the user query into a format that enables comparison and relevant search. This involves transforming the document collection (knowledge library) and the user-submitted query into numerical representations using embeddings from language models. These embeddings serve as numerical representations of concepts within the text.
Next, using the embedding of the user query, the relevant text is identified in the document collection through a similarity search conducted in the embedding space. The prompt provided by the user is then augmented with the searched relevant text and added to the context. Subsequently, the augmented prompt is passed to the large language model, and since the context now includes pertinent external data alongside the original prompt, the generated model output becomes more relevant and accurate.
RAG reference AWS implementation
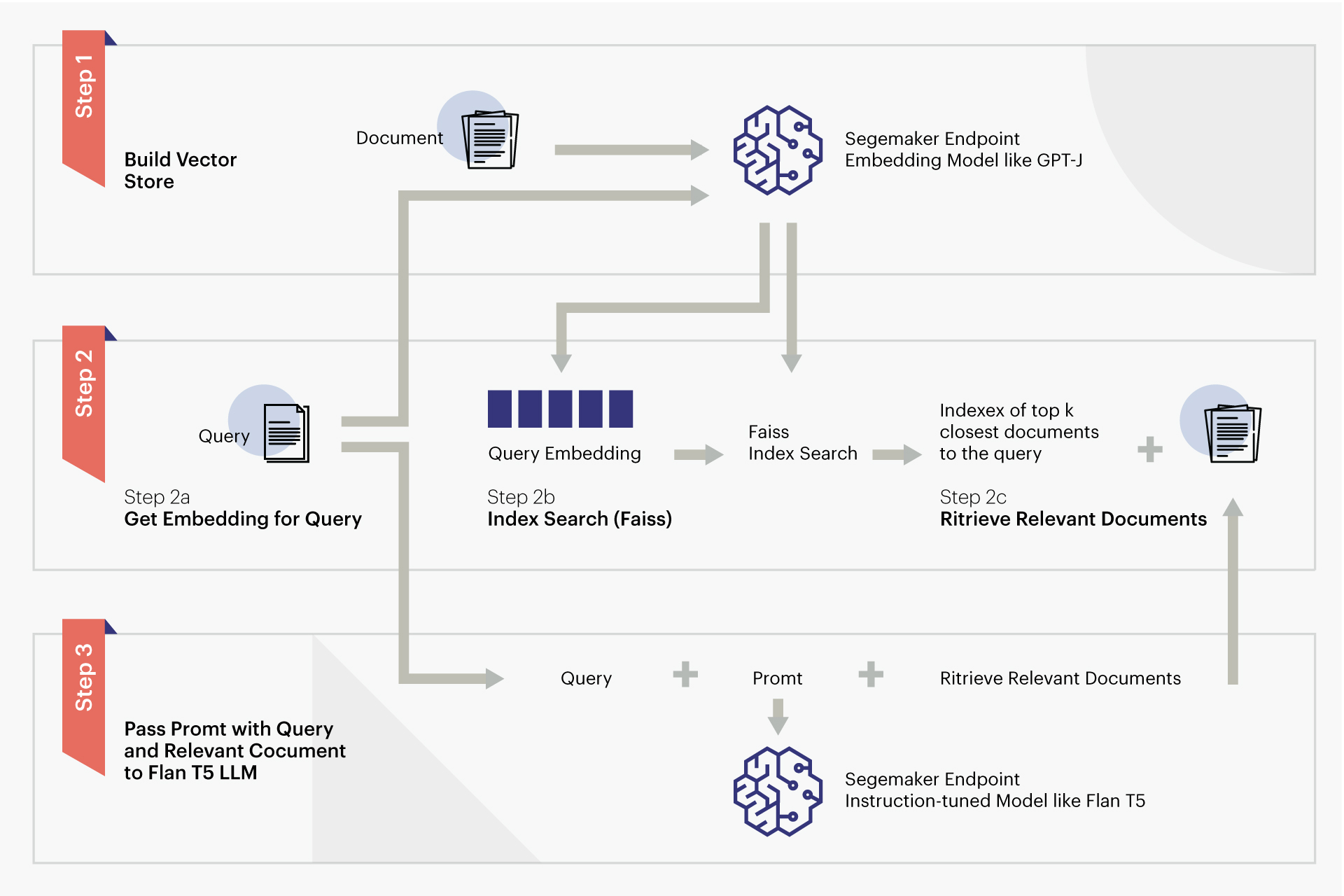
Credit – AWS - www.aws.amazon.com/blogs/machine-learning/question-answering-using-retrieval-augmented-generation-with-foundation-models-in-amazon-sagemaker-jumpstart/
RAG reference Azure ecosystem leveraging Azure Managed Services
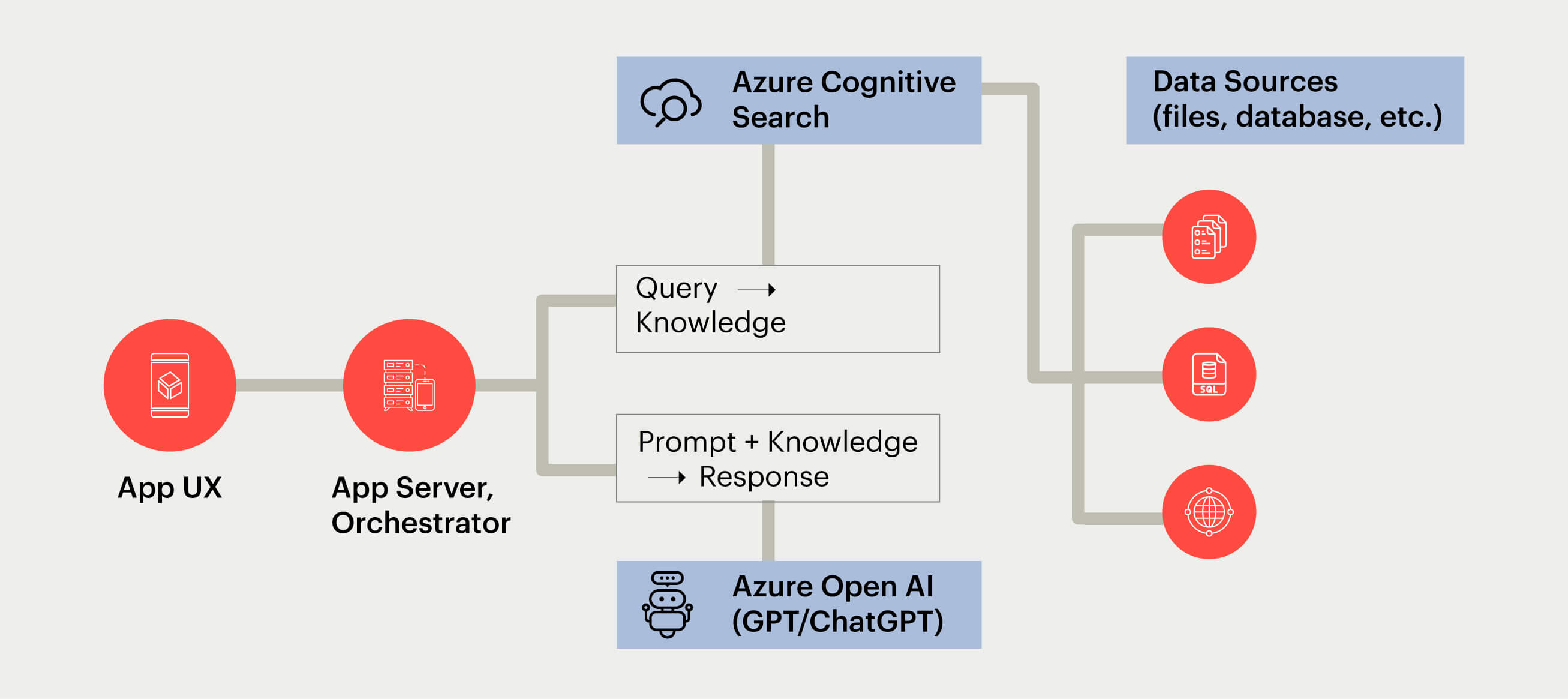
Credit - Azure - www.github.com/Azure-Samples/azure-search-openai-demo
Tremendous promise
In conclusion, the ecosystem and frameworks around generative AI are continuously maturing, bringing exciting possibilities and innovative applications to the forefront. As these technologies progress, we can expect to witness even more sophisticated and versatile solutions that cater to a wide array of industries and use cases. Embracing and staying abreast of these developments will empower enterprises and individuals to harness the full potential of generative AI and LLMs, revolutionizing how we interact with AI-driven systems and unlocking new realms of creativity and problem-solving. The future holds tremendous promise, and the journey toward fully unleashing the capabilities of generative AI has just begun.